Traefik 두번째 PR 기여 회고
Traefik 오픈소스 프로젝트에 두 번째로 기여하게된 limit-rps 어노테이션 지원 작업 내용을 공유하려 합니다.
배경
Kubernetes 환경에서 NGINX Ingress를 사용하던 유저들이 Traefik으로 마이그레이션할 때 가장 많이 찾는 기능 중 하나가 바로 Rate Limiting 입니다. NGINX에서는 nginx.ingress.kubernetes.io/limit-rps 라는 한줄의 설정으로 초당 요청 수를 제한할 수 있는데, 이를 Traefik에서도 동일하게 사용할 수 있도록 만드는 것이 이번 PR의 목표였습니다.
난관
Leaky Bucket vs Token Bucket
두 엔진이 사용하는 Rate Limit 알고리즘이 다르다는 점이 있었습니다.
NGINX (Leaky Bucket) : 일정한 속도로 요청이 빠져나가게 하는 방식입니다. 요청이 갑자기 몰리면, 그 즉시 503 Service Unavailable 에러를 내뱉으며 요청을 거절합니다.
Traefik (Token Bucket) : 일정한 속도로 토큰이 생성되고, 요청이 올 때마다 토큰을 하나씩 집어가는 방식입니다. 토큰이 없으면 요청이 거부되는데, 이때 492 Too Many Requests를 반환합니다.
Traefik과 NGINX가 사용하는 버킷 방식이 근본적으로 다르기 때문에 이를 고려하지 않고 수치만 그대로 옮길 경우, 사용자는 예상치 못한 트래픽 차단이나 성능 저하를 경험할 수 있습니다.
NGINX가 사용하는 Leaky Bucket 알고리즘에 대한 설명은 아래 두 곳에서 확인하실 수 있습니다.
- https://blog.nginx.org/blog/rate-limiting-nginx
- https://nginx.org/en/docs/http/ngx_http_limit_req_module.html
설계
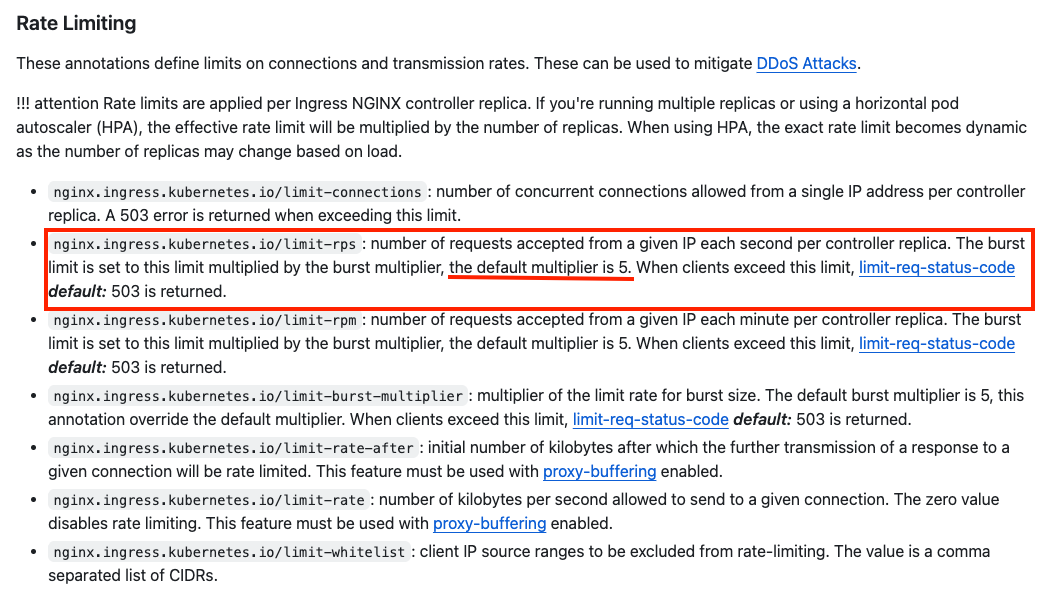
서로 다른 알고리즘을 사용하면서도 유저가 동작의 이질감을 느끼지 않게 하려면 어떻게 해야 할까요? 메인테이너의 리뷰에서 NGINX Ingress는 5배의 버스트 배수를 사용하고 있기 떄문에, 유저들의 사용 경험을 일관되게 유지하기 위해서 Traefik 측에서도 5를 기본값으로 쓰는 것이 어떻냐는 제안을 받았습니다.
NGINX가 5배의 배수를 두는 이유?
NGINX가 5배의 배수를 두는 이유는 네트워크의 일시적인 지연이나 아주 짧은 스파이크 트래픽이 발생했을 때, 이를 오류로 간주해 바로 차단하기보다 잠시 대기시켜 처리해주기 위함입니다.
- kubernetes docs 중...
곧바로 작업에 들어가 배수 설정을 진행했고, 문서 포맷과 코드 베이스 정리 후 머지 되었습니다!
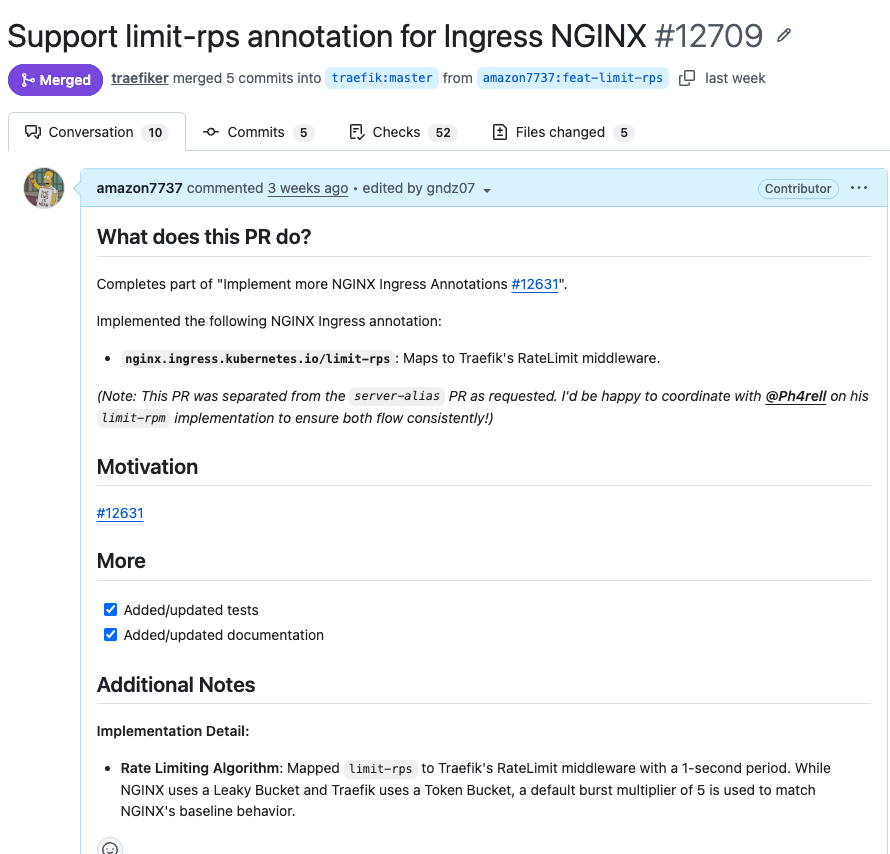
처음에는 특정 기능의 설정값이나 배수를 정할 때 어떤 기준으로 설정해야할지 몰랐습니다. 하지만 이번 기여를 통해 공식 문서와 기술 스펙이라는 명확한 근거에서 기준을 세우면 된다는 것을 배웠습니다.