600명 사용자 서비스를 위한 무중단 아키텍처 설계기
부산 지역 공유대학 학생 약 600명을 위한 수강 후기 플랫폼을 개발하며, 저희 팀은 중요한 기로에 섰습니다. "과연 이 규모의 서비스에 복잡한 분산 서버 구조가 정말 필요할까?"라는 근본적인 질문이었습니다. 이 글은 단순한 성능 문제를 넘어 서비스의 지속 가능성, 즉 '가용성(Availability)' 에 집중하여 단일 서버의 위험을 제거하고 무중단 운영 환경을 구축하기까지의 고민과 해결 과정을 담은 기록입니다.
설계 목표 및 배경
본 서비스는 예비 창업 단계의 현실적인 제약 사항인 서버 비용 부담 최소화를 최우선으로 고려하여 설계되었습니다.
목표는 Oracle Cloud Infrastructure(OCI) Free Tier의 저성능 인스턴스 (1vCPU, 1GB RAM) 을 활용하여, 최저 서버 비용 으로 최대한의 가용성 과 처리량 을 확보하는 것이었습니다. 즉, 최저 서버 비용으로 뽑아낼 수 있는 최대 가용성 에 도전했습니다.
현실적인 서비스 규모 가정
수강후기 시스템의 가용성 목표 규모는 부산 공유대학 의 환경을 기반으로 설정했습니다.
- 가정 범위 : 부산 지역 12개 대학의 학생들이 공유 대학의 강의를 수강하는 환경을 기준으로 합니다.
- 최대 동시 사용자 설정 : 서비스의 잠재적인 최대 사용자 수를 600명으로 설정하고, 이들을 대상으로 안정적인 서비스를 제공하는 것을 목표로 합니다.
- 가용성 목표 : 이 600명의 사용자가 시스템을 이용할 때, 피크 시간대에 시스템이 지연되거나 오류를 발생시키지 않고, 기능적 가용성을 보장하는 것을 최상위 목표로 삼습니다.
동시 사용자 수는?
- 동시 사용률 : 전체 사용자 수(600명)가 모두 동시에 활동하는 경우는 거의 없습니다. 일반적으로 **전체 사용자 중 약 5% ~ 15%**를 피크 시간대의 실제 동시 활동 사용자로 가정합니다.
- 10% 적용 : 부산 공유대학 600명 규모에 10%의 동시 접속률을 적용하면 60명이 됩니다.
- 의도 : 따라서 60명을 잡게 되었고, 이 수치로 테스트하여 가장 바쁜 시간에 시스템이 무너지지 않는지를 검증 하고자 했습니다.
단일 장애 지점(SPOF)의 위험성
| 문제유형 | WAS 1대 운영 시의 위험요소들 |
|---|---|
| 소프트웨어 장애 | WAS 메모리 누수나 런타임 오류 시, 서비스가 완전히 중단됨. |
| 인프라 장애 | 호스트 머신, 네트워크 문제 등 EC2 인스턴스 자체 장애 발생 시, 서비스 중단. |
| 배포 장애 | 새로운 버전 배포 시, 서비스 중단 시간이 발생하며, 배포 실패는 직접적인 오류 노출로 이어짐. |
단일 장애지점(SPOF)은 서비스의 가용성을 저하시키고, 서비스의 지속 가능성을 위협합니다. 한 대의 서버가 장애가 발생하면, 전체 서비스가 장애가 발생할 위험이 있습니다.

현재 수강후기 시스템은 단일 서버로 WAS를 구동중입니다. 이에 따라서, 단일 장애 지점을 피하고 부하를 분산하기 위해 Scale Out을 진행하였습니다.
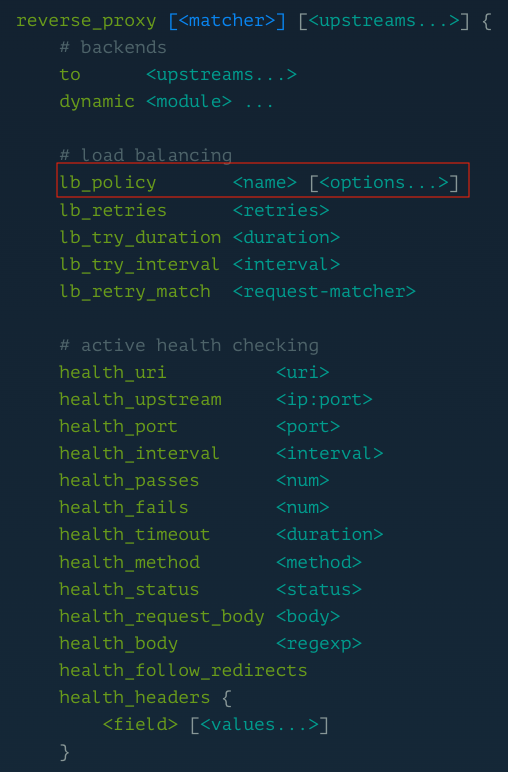
해결 과정 : Caddy를 이용한 로드밸런싱 및 헬스 체크
먼저, 왜 헬스 체크 기능을 도입하였는지 설명드리도록 하곘습니다.
제가 고려한 로드밸런싱 전략은 3가지가 있습니다.
- 가장 적은 요청으로 보내기 (least_conn)

your.domain.com {
reverse_proxy PUBLIC-IP-1:8080 PUBLIC-IP-2:8080 {
lb_policy least_conn
}
}
현재 연결 수가 가장 적은 서버로 요청을 보냅니다. 부하 분산에 유리합니다.
- IP 해시 (ip_hash) : 클라이언트의 IP 주소를 기반으로 요청을 항상 같은 서버로 보낸다. (세션 유지에 유리)

그러나 위 두 방법은 두 서버 중 한대가 다운되더라도, 웹서버가 자동으로 감지하고 작동하는 서버로만 트래픽을 보내도록 구성하는 요구사항에 충족하지 않았습니다. 따라서, 헬스체크를 적용하면 가용성을 더 보장할 수 있습니다.
- 헬스 체크 (Health Checks)
Caddy는 기본 reverse_proxy 설정만으로도 로드밸런싱을 수행하지만, 서버 장애를 감지하고 트래픽을 우회하는 기능을 사용하면 가용성이 크게 향상됩니다. 이 기능은 헬스 체크(Health Check) 를 통해 설정하며, 우회 시간은 감지 주기에 따라 결정됩니다.
Caddy Webserver 공식 문서를 참고하면, 헬스체크 기능을 제공하는 구성이 존재합니다.

따라서, 아래와 같이 헬스 체크 관련 지시어를 추가하여 설정할 수 있습니다.
your.domain.com {
reverse_proxy 192.168.1.10:8080 192.168.1.11:8080 {
# 1. 헬스 체크 엔드포인트 설정
# WAS 서버가 '200 OK'를 응답하는 상태 확인용 API 경로를 지정합니다.
health_uri /health
# 2. 헬스 체크 주기 (Interval)
# 5초마다 WAS 서버의 /health 경로로 요청을 보내 상태를 확인합니다.
health_interval 5s
# 3. 헬스 체크 허용 오차 (Tolerance)
# 헬스 체크가 몇 번 실패해야 해당 서버를 '다운' 상태로 간주할지 지정합니다.
health_tolerance 2
# 4. 복구 대기 시간 (Grace Period) (선택 사항)
# 서버가 다운 상태에서 '정상' 상태로 돌아왔을 때, 다시 로드 밸런싱에 포함시키기 전에
# 잠시 기다리는 시간 (WAS가 완전히 안정화될 시간을 줍니다.)
health_resume_grace_period 30s
}
}
- 동작 및 우회 시간:
- 장애 감지 시간 : Caddy는
health_interval과health_tolerance를 통해 장애를 감지하빈다.- WAS-A가 다운되었을 때, Caddy는 5초마다 확인하고, 2번 연속 실패(
health_tolerance)하면 다운으로 간주합니다. - 총 장애 감지 시간 : 5초 X 2 = 10초
- WAS-A가 다운되었을 때, Caddy는 5초마다 확인하고, 2번 연속 실패(
- 우회(Failover) : Caddy는 WAS-A가 다운으로 감지되는 즉시 모든 트래픽을 WAS-B로 우회(Failover)합니다.
- Caddy는 해당 서버가
health_uri요청에 대해 HTTP 2xx 응답을 하지 않으면 자동으로 리버스 프록시 목록에서 제외하고, 응답이 정상화되면 다시 포함시켜 서비스의 가용성을 자동으로 유지합니다.
- 장애 감지 시간 : Caddy는

위는, 헬스 체크 기능을 구현하여 동작하는 시스템 구조 예시입니다.
- Health Check 엔드포인트에 관한 Spring Boot Controller 예제
@RestController
public class HealthCheckController {
@GetMapping("/health")
public ResponseEntity<Map<String, String>> checkHealth() {
Map<String, String> response = new HashMap<>();
response.put("status", "UP");
response.put("service", "WAS Application");
response.put("version", "1.0.0");
return ResponseEntity.ok(response);
}
}
이러한 엔드포인트를 작성하여 Caddy Webserver가 해당 서버의 헬스 체크를 진행하며 로드밸런싱에서 발생할 수 있는 한쪽 서버가 다운되었을때의 동작에 대해서 알아보았습니다.
분산된 WAS 서버에 대한 접근은 어떻게 처리하였는가?

하위 WAS 서버를 2대로 분산시키게 되면, 클라이언트의 요청은 Gateway 서버를 지나 WAS 서버 각각으로 도달하게 됩니다. WAS 서버에 대한 접근을 굳이 모두에게 줄 필요가 있을까요?
OCI 서브넷 보안그룹 구성
서브넷 보안그룹(Subnet Scurity Group)은 클라우드 인스턴스에 대해 인바운드와 아웃바운드 트래픽을 제어하는 가상의 방화벽 역할을 합니다. 인스턴스 단위로 적용되며 인스턴스에 하나 이상의 보안그룹을 설정할 수 있습니다.

- 주소값들은 모두 가렸습니다. 핵심은 인바운드(Inbound) 수신 규칙에서 Gateway 인스턴스의 PUBLIC-IP 단 하나만 허용하도록 하는 것입니다.
- 이렇게 설정하면, 외부에서의 접근을 차단할 수 있습니다.
따라서, 서브넷 보안 그룹에서 접근을 제한해, WAS 서버의 보안을 향상 시켰습니다.

Gateway 인스턴스를 두어 WAS를 내부로 숨길 수 있는 구조가 되었습니다.
설계안 성능 테스트 진행
마지막으로, 해당 구조에 대한 성능을 평가하기 위해 apache bench를 이용하여 성능 테스트를 진행해보았습니다.
일반 지표
| 지표 | 결과 | 단위 |
|---|---|---|
| Concurrency Level | 60 | |
| Time taken for tests | 4.162 | seconds |
| Complete requests | 600 | |
| Failed requests | 0 | |
| Non-2xx responses | 600 | |
| Requests per second | 144.15 | [#/sec] (mean) |
| Time per request | 416.241 | [ms] (mean) |
| Transfer rate | 88.54 | [Kbytes/sec] received |
Connection Times (ms)
| 구분 | min | mean[+/-sd] | median | max |
|---|---|---|---|---|
| Connect | 26 | 87 ± 38.5 | 95 | 364 |
| Processing | 27 | 242 ± 307.9 | 124 | 1565 |
| Waiting | 25 | 241 ± 307.4 | 123 | 1563 |
| Total | 94 | 329 ± 296.7 | 218 | 1613 |
지연 시간 백분위 (Percentage of the requests served within a certain time)
| 백분위 | 시간 (ms) |
|---|---|
| 50% | 218 |
| 66% | 287 |
| 75% | 299 |
| 80% | 305 |
| 90% | 597 |
| 95% | 1156 |
| 98% | 1371 |
| 99% | 1375 |
| 100% (longest) | 1613 |
성능 테스트 결과에서 DB I/O 병목의 강력한 징후를 캐치할 수 있는 핵심 지표는 Waiting 시간입니다.
DB I/O 병목 현상을 진단할 수 있는 근거는 Connection Times 섹션의 Waiting 시간과 Processing 시간의 관계를 분석하는 것입니다.
| 지표 | 결과 (mean) | 분석 |
|---|---|---|
| Processing (서버 처리 시간) | 242 ms | WAS(Web Application Server)가 요청을 받아 CPU를 사용하여 로직을 실행하는 데 걸린 시간. |
| Waiting (대기 시간) | 241 ms | WAS가 요청을 처리하는 동안 **백엔드 자원(주로 DB)**의 응답을 기다리는 데 걸린 시간. |
| Total (총 시간) | 416.241 ms | 요청이 시작되어 응답이 완료되기까지 걸린 총 시간 (Connect + Processing). |
-
Waiting 시간의 역할: HTTP 요청이 서버에 도달한 후, 서버가 응답 바디의 첫 바이트를 보내기 시작할 때까지 걸린 시간입니다. WAS가 DB에 쿼리를 보내고 결과를 받아올 때까지의 시간이 여기에 포함됩니다.
-
분석: 평균
Waiting시간(241ms) 이 서버의 순수Processing시간(242 ms) 과 거의 동일 합니다. 이는 서버가 요청을 처리하는 시간의 거의 절반을 다른 자원의 응답을 기다리는 데 소모했다는 의미입니다. -
결론:
Waiting시간이Processing시간과 같다는 것은 DB 쿼리 실행 및 데이터 I/O가 전체 요청 처리 시간에서 가장 큰 비중을 차지하는 병목 지점일 가능성이 매우 높습니다. -
만약 순수 애플리케이션 로직(CPU 작업)이 병목이었다면,
Processing시간은 길고Waiting시간은 짧았을 것입니다. 하지만 현재는 WAS가 DB 응답을 받지 못해 지연되고 있음을 보여줍니다.
따라서, 이 결과를 바탕으로 DB I/O 을 줄이기 위한 방안을 고민해볼 수 있습니다.
첫번째로 해당 시스템에서 현재, 캐시를 활용하고 있지 않습니다. 해당 테스트는 한 종류의 조회 요청을 기반으로 하였기에, 자주 조회 되는 요청에는 캐싱을 활용하는 방법이 있을것 같습니다.
두번째로 데이터베이스 이중화를 진행해, 부하 분산을 주는 것입니다. DB I/O 자체를 줄이는 것은 아니지만 데이터베이스 서버 입장에서의 부하 분산을 이루는 것입니다. 단점으로는 데이터 일관성을 맞추기 위한 또 큰 작업이 필요하다는 것입니다.
위 두 전략은 모두 Waiting 시간을 줄이는데 좋은 방안이 될 수 있습니다. 마지막으로는 데이터베이스 서버의 스케일업이 있습니다.
마무리
이처럼 명확히 드러난 다음 과제, 즉 DB 쿼리 튜닝과 WAS 최적화 단계를 진행하기 위해 예비창업 지원 사업 선정을 발판으로 삼으려 했습니다. 만약 사업이 최종 선정되었다면, 확보된 확장성 기반 위에서 성능 최적화 단계를 밟아 나가 안정적이고 빠른 수강후기 공유 시스템이라는 훌륭한 서비스 결과물을 만들 수 있었을 것입니다.
안타깝게도, 저희가 예상치 못한 비즈니스적 문제 (팀 해체..) 로 인해 프로젝트가 잠정 중단되면서, 이 흥미로운 최적화 단계를 직접 경험해보지 못한 점은 가장 큰 아쉬움으로 남습니다.
그럼에도 불구하고, 요구사항 분석 → 규모 예측 → 아키텍처 설계 → SPOF 제거 → 성능 테스트를 통한 검증에 이르는 모든 과정을 실제 엔지니어링 관점에서 주도적으로 경험할 수 있었습니다. 특히, 단순한 이론이 아닌 ab 테스트를 통해 Non-2xx 응답과 같은 예상치 못한 치명적인 오류를 발견하고, 인프라와 애플리케이션의 경계를 오가며 문제를 진단하는 과정은 엔지니어로서의 문제 해결 능력을 크게 성장시키는 소중한 경험이 되었습니다.